

In this blog we address the freedoms that attackers enjoy with regard to Microsoft Remote Procedure Call (MSRPC). We start by looking at the current detection and prevention limitations and end with an introduction to our solution. You can find our experimental fork of Zero Networks’ RPC Firewall here.
Defensive RPC Challenges
Attackers abuse MSRPC in nearly every incident involving multiple Windows systems. The uses for it are vast and include lateral movement, credential dumping, enumeration and forced authentication. In many cases, RPC attacks are preferable to on-host execution as they minimize artifacts. It is a significant blind spot for many organizations that leads to failure to identify incidents or inadequate scoping.
Identifying RPC abuse is notoriously difficult. In fact, one mark of an advanced defender is the ability to accurately assess a variety of malicious RPC attacks. This is due to the lack of a single authoritative RPC event. Defenders must correlate disparate log sources and the artifacts are often specific to the attack technique. The data is split between the invocation, which is captured by ETW or connection logs, and the result, which may or may not be captured depending on the service. If the SOC is lucky enough to have a SIEM that can subsearch, they are still subject to a heavy investigative workload due to the imprecise and inferential nature of these detection techniques. Our efforts are imprecise and prone to error in the best cases, and in the worst, we are completely lacking one side of the invocation/result equation.
RPC Primer
Microsoft RPC is complex, but it has a simple goal: allow developers to invoke remote functions as they would a local function. As long as the client and server share the same RPC interface, programmers can focus on application logic without concerning themselves with network communication, data serialization, or authentication. They simply connect, or bind, to a server and call the function.
The RPC client and server accomplish this abstraction with the use of stubs and the RPC runtime (rpcrt4.dll). The client stub is a bit of code that’s created by a Microsoft tool called the MIDL (Microsoft Interface Definition Language) compiler. When a developer creates an RPC client, they give the MIDL compiler an interface definition. The interface definition is shared between the client and server and defines the procedure’s methods and the argument types. The stub created by the MIDL compiler marshals (or transforms) each argument based on the interface definition. The result is a buffer of NDR (Network Data Representation) data. The RPC runtime takes the NDR data and sends it to the server.
The server stub unmarshals the NDR data according to the shared interface definition. Each argument is moved into registers and/or the stack and the stub calls the server function just like any other method.
To analyze a suspicious RPC event, we need to know:
- The source workstation - if the client is remote
- The calling process PID - if the client is local
- The user that made the request
- The service (interface UUID)
- The procedure the client calls (ProcNum)
- The result of the call
Developing an Authoritative RPC Event
When an RPC server receives a connection, it executes a callback that handles the incoming NDR data. An OSF_SCALL object processes the RPC call. It receives information from the client via an instance of OSF_SCONNECTION. Then, it organizes the NDR data, binding handle, interface information and ProcNum (which denotes the method) into an _RPC_MESSAGE structure. This is passed to one of a few stub entry points (e.g. NdrStubCall2) that marshal the parameters and invoke the server code. Once the server is finished processing, the instance of OSF_SCALL sends the marshalled output back to the client.
By the time execution reaches OSF_SCALL::DispatchHelper, we theoretically have all the information we need. We have the raw data in NDR format, the client IP address and the means to extract the account that initiated the call. In fact, this is where Microsoft writes server call start events to the Microsoft-Windows-RPC ETW provider. We could try to hook DispatchHelper, or its dispatch functions DispatchToStub and DispatchToStubWithObject, and “fix” the telemetry. But hooking member functions and accessing their variables is less than ideal.
The next option is to hook the exported stub entry points since OSF_SCALL passes a complete _RPC_MESSAGE structure to them. Then, we could parse this structure to get us the critical information we need. In fact, an existing, underutilized, open-source project does just that.
Zero Networks’ RPC Firewall project hooks every server stub entry point:
- NdrStubCall2
- NdrServerCallAll
- NdrAsyncServerCall
- Ndr64AsyncServerCallAll
- Ndr64AsyncServerCall64
- NdrServerCallNdr64
Then, it evaluates each call and resolves user and network address. It also has a dead-simple configuration that allows you to specify exactly what you want to block or audit by: ProcNum, interface UUID, user, group, source address and protocol sequence. The biggest advantage of this capability is the ability to block a lot of forced authentication techniques outright.
This is an example RPC Firewall log entry. RPC calls to hooked processes generate event 3 in a special RPCFW log.
This gets us most of the way to our goal. We have the source IP, user, interface and ProcNum. We also no longer have to deal with ETW (phew). However, we’re still missing the result.
In the example above, we can see that an RPC function was called by a user on a remote system. It could potentially be a forced authentication attack. But we can’t see where the attacker is sending the request. If we’re lucky we could correlate an authentication or network event. But this is suboptimal.
Since RPC FireWall hooks the server stub entry points, we have the full _RPC_MESSAGE structure. This contains a pointer to the raw marshalled NDR data.
We could parse this data to extract the arguments. But, surprisingly, there doesn’t seem to be any simple C++ NDR parser that will give us what we need in the way we need it. It seems most people who develop for RPC do so in the conventional way - with the Microsoft MIDL compiler.
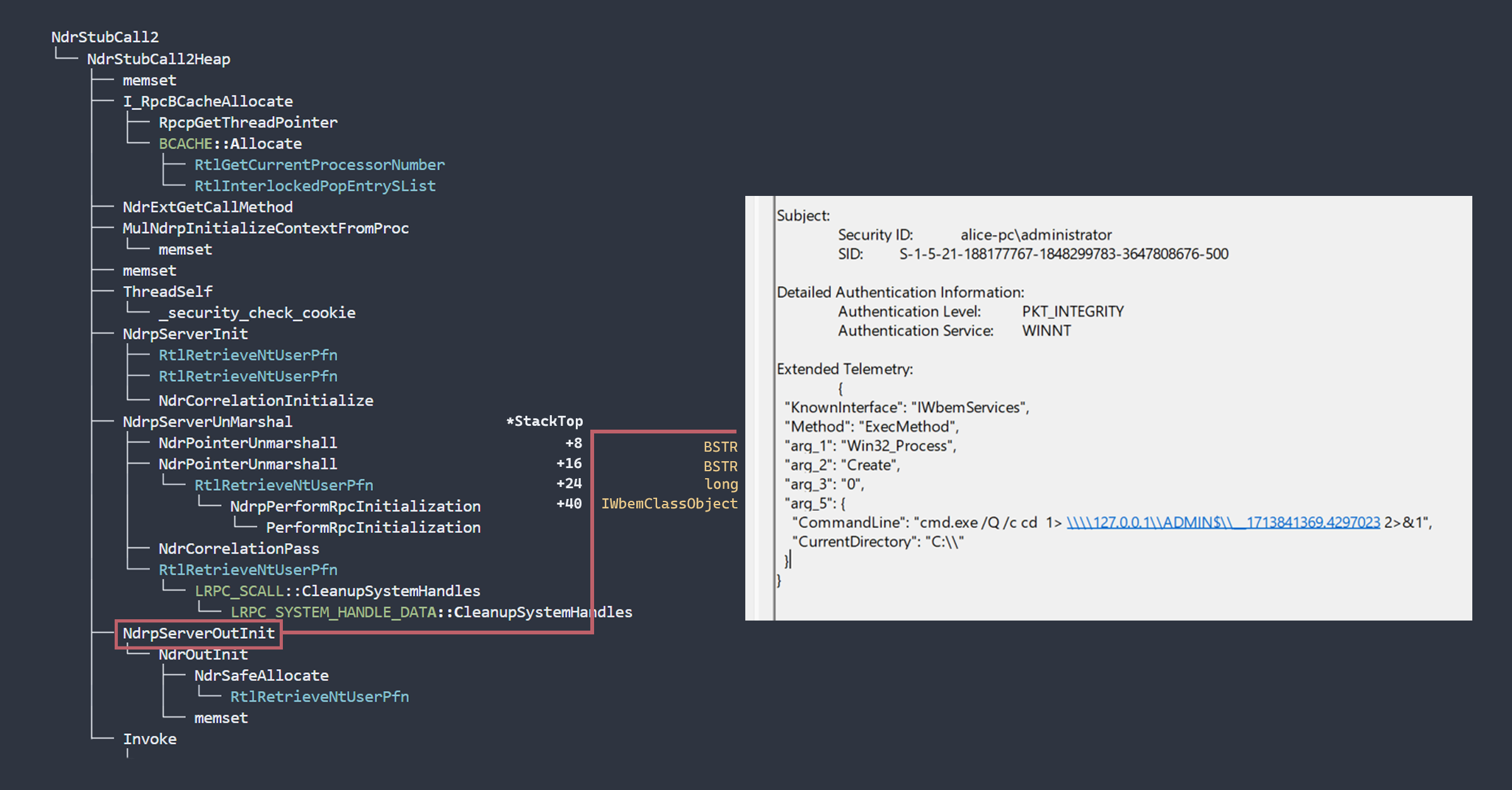
There is a hooking candidate that will allow us to access the unmarshalled arguments. It exists deeper in the code path, just prior to invocation. By the time the server executes NdrpServerOutInit, the server stub arguments have been prepared by NdrpServerUnMarshal. This Unmarshalling function parses each argument from the original _RPC_MESSAGE and prepares it as a stack - 8 bytes for each argument (x64). This is much more fun than writing an NDR parser. We can just sandbag the server stub and steal everything it has prepared in _MIDL_STUB_MESSAGE->StackTop. All that’s left to do is interpret the data based on the interface definition and we can log the arguments.
There is a relevant C++ project that parses compiled RPC interfaces: RpcView. It is a monitoring tool that extracts RPC information from running processes, ostensibly for the purpose of discovering hidden RPC functionality. It derives MIDL-compatible interface definitions that you could use to create an RPC client (fuzzer).
Even if you aren’t looking to write a fuzzer, RpcView is an interesting project to explore. The top left window shows you where each process is listening for RPC connections. This is handy to know as a defender. The process of clicking through the different services and looking at their listeners is much more impactful than reading Microsoft protocol definitions.
While the RpcView decompiler code unravels the interface definition, we need something that iterates through the server argument stack. We can use the RPC view types as a base to do this, but it won’t be as precise as a 1 to 1 decompilation. This is because the server function may not interpret the data as it’s defined in the interface. For example, the SchRpcRegisterTask defines arg_3 of type long, but the function itself interprets this as a DWORD for the flags argument. This isn’t really a problem, but interpreting it as a long may be meaningless to an analyst.
We may also need to interact with objects, especially for WMI calls, to interpret what the attacker is doing. Lucky for us, most of the RPC functions we’re really interested in are simple types, or one-level pointers (strings). We can tackle the objects on a case-by-case basis.
The Result
At the time this blog is published, our RPC Firewall fork logs simple types, wstrings and WMI objects. This covers the majority of the RPC functions we’re interested in. It also resolves well-known interfaces and their methods to their common names. This is what Impacket wmiexec.py looks like:
This is quite nice because it allows us to write detection logic with all of the information we need. No subsearching, no additional analyst investigation. We have the malicious command and the culprit. Here’s an example of how we can use additional telemetry to expose a WMI event subscription attack. Detecting this usually requires the correlation of multiple events or manual analysis.
Hopefully you’re both blocking and auditing the known forced authentication techniques. If so, we can extract the attacker’s relay server IP address and use it for scoping.
The biggest limitation of this approach is that we can’t hook protected processes with RPC Firewall. This takes Service Control Manager (MS-SCMR) and the various RPC servers in LSASS off the table. Some of the services we can monitor include the Task Scheduler, Print Spooler, Windows Management (WMI), Remote Registry, Endpoint Mapper, etc. So, not perfect, but not bad!
Future Possibilities
The most obvious next question is “can this be used as a preventative control.” Yes! We could extend the configuration and block the RPC call arguments. For example, we could potentially limit forced authentication methods to specific IPs. We could also scope down which WMI classes and methods are allowed. If we can’t outright block the WMI interface, we could create an allow or deny list to prevent common lateral movement techniques. This functionality is not implemented, but in theory it’s not much different from how RPC Firewall currently blocks RPC calls.
We can also use this for local RPC calls. Attackers frequently abuse local RPC for various reasons including persistence, defense evasion, enumeration, etc. While RPC Firewall is primarily designed to block network attacks, we can simply remove this condition from the code and log the attempt just like any network-based RPC call. We can also resolve the source process PID with a call to RpcServerInqCallAttributes.
This produces a lot of noise. To make something like this work we would ideally need to extend the RPC Firewall configuration to incorporate argument values in the auditing policy.